Its Not at all About Storage Space …
Aside from the general re-architecture from a central repository to a plethora of general purpose meta-stores and digests on that architecture to increasingly specific met-store and digests to just one place, there are but two themes to Eureka. First, reduce the overall wasted space when storing and accessing data and secondly, reduce the overall access time. This should really should read
Reduce the overall access time.
Reduce the overall access time.
!!! Reduce the overall access time !!!
The functionality and statistics are a means to the end, which are enabled by and improved with larger data, and that is tolerable with quicker processes, quicker turnaround and faster overall access time. Quicker turnaround time results in more analysis, results in better understanding of the data, results in a better applications, utilizing larger data, more insights and so on.
Consider space, if you have one server at capacity and you want to double the space of that capacity in almost all cases you could easily partition that job on two servers now at twice the relative speed as before. The problem is that this is only the best outcome, soon to be disturbed if for any reason the now split job in such a way that the work largely independently processed across the servers. The upside 2x improvement, the downside 1 million x degradation as every context level of the program is broken right down to the ethernet packet if an when that server just a single meter away must synchronize.
Buying more machines is cheap, but using them incorrectly can be very expensive. Compression in information retrieval, though perhaps originally about economizing the quicker more expensive memory, has been for a very long time about minimizing the relative slowness of memory movement and the locality of data. Even though the CPU clock rate has been relatively stagnant, the transistor count marches forward diving at least two different dimensions of better opportunity, mainly the CPU cores count and the instructions per clock cycle increase. Maintaining the highest utilization of concurrency within the CPU by reducing the starving out to cache levels fails and memory bus performance and the reduction of resource contention will be the biggest concern in a large data system now and into the short term future at least.
Consider also the fortuitous cycle that occurs as data increases in each unit of density. In such a case then offsets get smaller, which means that references can get smaller, then offsets get smaller again, which means references can get smaller. Densification acts to lessen cache failures and improves data locality meaning again concurrent operations are more likely to happen.
About Space
The amount of space required to store a sampling of William Shakespeare can be summed up in a single graph. It appears to be settling somewhat at a 75% overhead on top of the original text itself.
Note: The following graph is out of date. The current Eureka ratio appears to converge to 1.44.
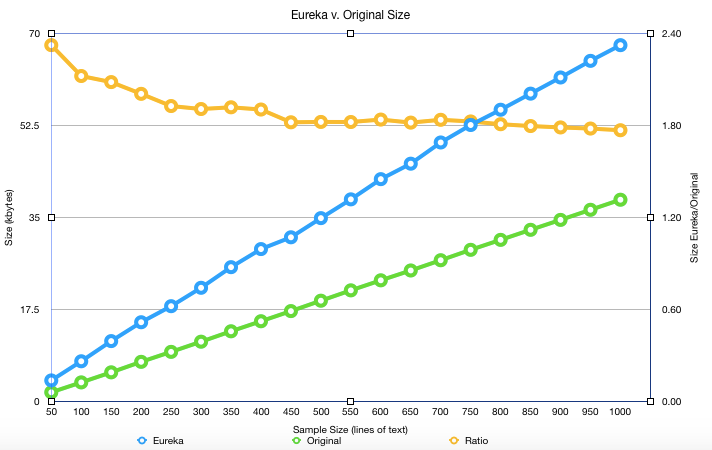
The horizontal axis indicates lines of Shakespeare ingested and each blue and green data point respectively indicate the size in kilobytes of the Eureka dataset and the original text respectively. The golden colored line is the ratio of the blue line over the red line, and the flattening out as we approach 1000 lines of text that Eureka is likely to require an approximately 75% overhead on top of the size of the text though it would be interesting to re-evaluate with documents of many magnitudes of size larger and many different types of documents.
I should note here that Eureka is limited most in ingesting information, however the paltry size of the can be explained better by a lack of resources more than anything else, there are no limiting constraints as designed aside from the relatively expensive potentially one time transformation of the original stream to an internal format.
Comparisons With Popular Search Indexers
As it was explained previously, Eureka Data stands to replace a vast amount of intermediate meta data and derivatives with a general purpose framework. Any one of these may easily exceed the 75% overhead above and as a collection they would generally exceed this by a great multiple.
Looking at just search engine indexing, a popular meta data service for all data and fields that are unstructured. The popular search tools Lucene and the more modern Elasticsearch seem to have a base line index (or overhead) cost of 2-3 and 0.5-1.5 times with modest indexing. You can see that its not even really reasonable to compare as these frameworks with Eureka as they are mainly crafted about selecting which parts of the original dataset that you would like to index, how deep you would index them and what kinds of ancillary data would you also like to derive in order to best utilize the resulting index.
In contrast the Eureka system is definitively complete and comprehensive. As the source of truth nothing can remain unindexed nor can any statistic necessary for recovery left uncollected. If anything were either unindexed or uncollected the Eureka method would not be able to recover all or a part of the data. Still Eureka at 75% overhead is extremely competitive and seems superior to state of the art techniques even using their own perspective.
A Necessary Perspective Change
How poorly the concepts fit together accentuates the problems of perspective that Eureka attempts to overcome. The concept of overhead must be addressed as it is problematic. William Shakespeare with full indexes and aggregate statistics is a lot more information than William Shakespeare without.
The rational follows. William Shakespeare in ascii format is much more information than the same text given a completely lossless operation of bzip (under best mode it compresses to 27% of its original size). However with the bzip version one could not directly make little intelligence of the data, nor could one skip an arbitrary amount into the text and make any intelligence at all. Knowing very little about the data directly without first decompression indicates that there is actually less information there.
Likewise William Shakespeare in ascii format is less information than an indexed version of the same text. While you can make intelligence of some part of William Shakespeare in ascii format directly, you cannot make intelligence or derive any information about all William Shakespeare directly. You also could directly skip some arbitrary number of bytes into the text and make intelligence of what you now read, but you cannot skip directly to a specific part intelligently without the added index to tell you where to go.
Scale this line of reasoning up with the following thought experiment. What if you had all the human readable information that there ever was in one place? Clearly this would be unintelligible. An objective analyst dropped into an arbitrary part of this enormous corpus would be many orders of magnitude more likely to be somewhere whose context they could little understand than be at say at a tweet that they published earlier in the day. If you were facing all the information that there ever was you would more likely than would never stumble across a context that was fully understood.
If the information were organized however you would directly find your tweet. To compile a list of similar tweets or to even understand the context of that one 140 character message would take considerable organization to aide the process. A program or even a cluster of coordinated programs would be a help, but only in a limited way. One program searching multiple orders of magnitude more quickly than the analyst, or a cluster of programs with multiple orders of magnitude faster search than the one program would both be quickly bogged down. The key is that the data is itself must be organized. That really is the only opportunity have an opportunity to even understand one aspect of the data.
Organization therefor is not overhead so much as creating data from data, or as per earlier example creating it from the great bard himself. With this concept in mind the contrast between Lucene, Elasticsearch and Eureka increases. Thinking from this perspective Lucene and Elasiticsearch are creating new information from their corpus, but in so far as they are incomplete, non comprehensive and less general they are bringing in much less information that Eureka hence are truly much less efficient than Eureka.
Efficiency
Luckily one should be able to emulate Eureka on Lucene or Elasitcsearch. You need only create a complete and full and index with no denormalization and all statistics possible. This would be an exercise in duplicating data in many formats, for example to achieve direct keyword regular expression matching some Lucene users play tricks such as index each word recursively at each letter in the word . You would have to invent a lot of mechanisms to pour in statistics and for instance multiple mechanisms to mark different levels of context such as sentence, paragraph, section document. The result would built up. The result would be huge!
I have some pretty clever codecs as part of Eureka, but more significantly than those or rather building upon those the efficiency is the result of all information being complete and self referential. Eureka couldn’t save information by not indexing something such as stop words, nor can it normalize all terms to UPPERCASE or stem terms. There is no statistic that can be discarded or even truncated in order to save space. The user is welcome to do that with their data stream if they like and for some applications it may actually make sense and save resources to discard or normalize their data, however doing any of these things within the Eureka format itself would break with concept of a self consistency and completeness and ultimately cost more in space than being designed to store it all.
[ To some degree stemming, and transformation is more about increasing recall (being less specific) than operational performance. Eureka can help here as the specificity could be guided interactively. Further with mixed case only permutations present in the token table get added to a mixed case join and searching for such permutations cost only one operation per letter (in contrast to hash table which would be 2^ letter) and managing them during a join is done through a light weight cursor. Unless a sizable (as in hundreds or thousands) of permutations of cursors exist perceptible performance degradation is unlikely. ]
Overall Access
The information in Eureka is organized for direct access, where direct access is shorthand for O(logk(n)), where k >> 2. This is not truly random access but approximately so. Possibly more important than the O(logk(n)), k >> 2 and O(k) is that wherever possible data locality has been preserved. For example the bits representing one word are directly adjacent to the bits representing the following word. The uncapitalized word is logically connected to its capitalized equivalent, etc.
The efficient packing of information within the architecture should be able to scale to quite large with near constant time performance for many of its operations.
Direct access to both local and corpus wide statistics allows for both query dynamic optimization and optimized hypothesis testing.